自组织映射 | 机器学习
发布 December 19, 2023 • 1 分钟 • 183 字
引言
在机器学习的广阔领域中,自组织映射(Self-Organizing Map,SOM)占据了一席之地。它是一种无监督学习的人工神经网络,用于数据的降维和可视化。今天,我们将深入探讨SOM的概念、定理、原理,并通过Python示例展示其在实际问题中的应用。
历史背景
SOM的提出源于对大脑皮层处理信息的方式的启发。Kohonen教授通过模拟这种生物学上的信息处理机制,创建了一种能够揭示数据内在结构的神经网络模型。从80年代初到现在,SOM已经在许多领域得到了广泛的应用,如金融分析、生物信息学、图像处理等。
概念
自组织映射(SOM)是由芬兰教授Teuvo Kohonen在1982年提出的一种无监督学习算法。它通过训练过程自我组织,形成一个拓扑结构,能够将高维数据映射到低维空间(通常是二维),同时保持数据的拓扑关系,这使得它在数据可视化方面特别有用。
与其他机器学习技术的对比
与传统的监督学习方法如深度学习神经网络和支持向量机等相比,SOM提供了一种不同的视角来处理和理解数据。SOM不依赖于标签数据,更专注于揭示数据的内在关系和结构。此外,与主成分分析(PCA)等其他降维技术相比,SOM保留了数据的非线性关系,这在许多复杂数据集的分析中是非常重要的。
原理
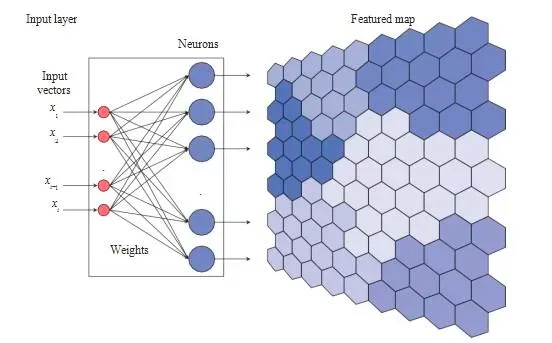
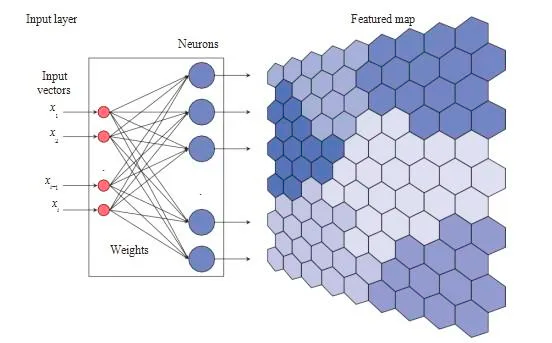
SOM的基本原理是将输入向量映射到一个二维的网格上。每个网格点(神经元)都有一个与输入空间维度相同的权重向量。通过竞争学习,SOM能够调整这些权重向量,使得相似的输入被映射到相近的神经元上。
- 竞争阶段: 对于每个输入向量,找到与之最相似(通常是欧氏距离最小)的神经元。
- 调整阶段: 调整胜出神经元及其邻域内的权重向量,使它们更靠近输入向量。
流程
-
初始化: 随机初始化神经元的权重向量。
-
竞争: 对于每个输入样本,找到最相似的神经元。
-
合作: 确定胜出神经元的邻域。
-
适应: 调整胜出神经元及其邻域内神经元的权重。
-
重复: 重复步骤2-4,直到网络稳定。
应用场景
- 数据可视化:将复杂的高维数据集映射到二维空间,以直观的形式展现数据结构。
- 聚类分析:自动发现数据中的模式和群组。
- 特征提取:在降维过程中提取数据的关键特征。
- 异常检测:识别数据集中的异常或离群点。
实际应用案例
在金融领域,SOM被用于信用评分系统,通过分析客户的历史交易数据来预测其信用风险。在生物信息学中,SOM用于分析和分类复杂的基因表达数据。在图像处理领域,SOM用于图像压缩和特征提取,帮助提高图像识别的效率和准确性。
Python完整示例
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.preprocessing import StandardScaler
from minisom import MiniSom
# 数据加载
data = load_iris()
X = data.data
y = data.target
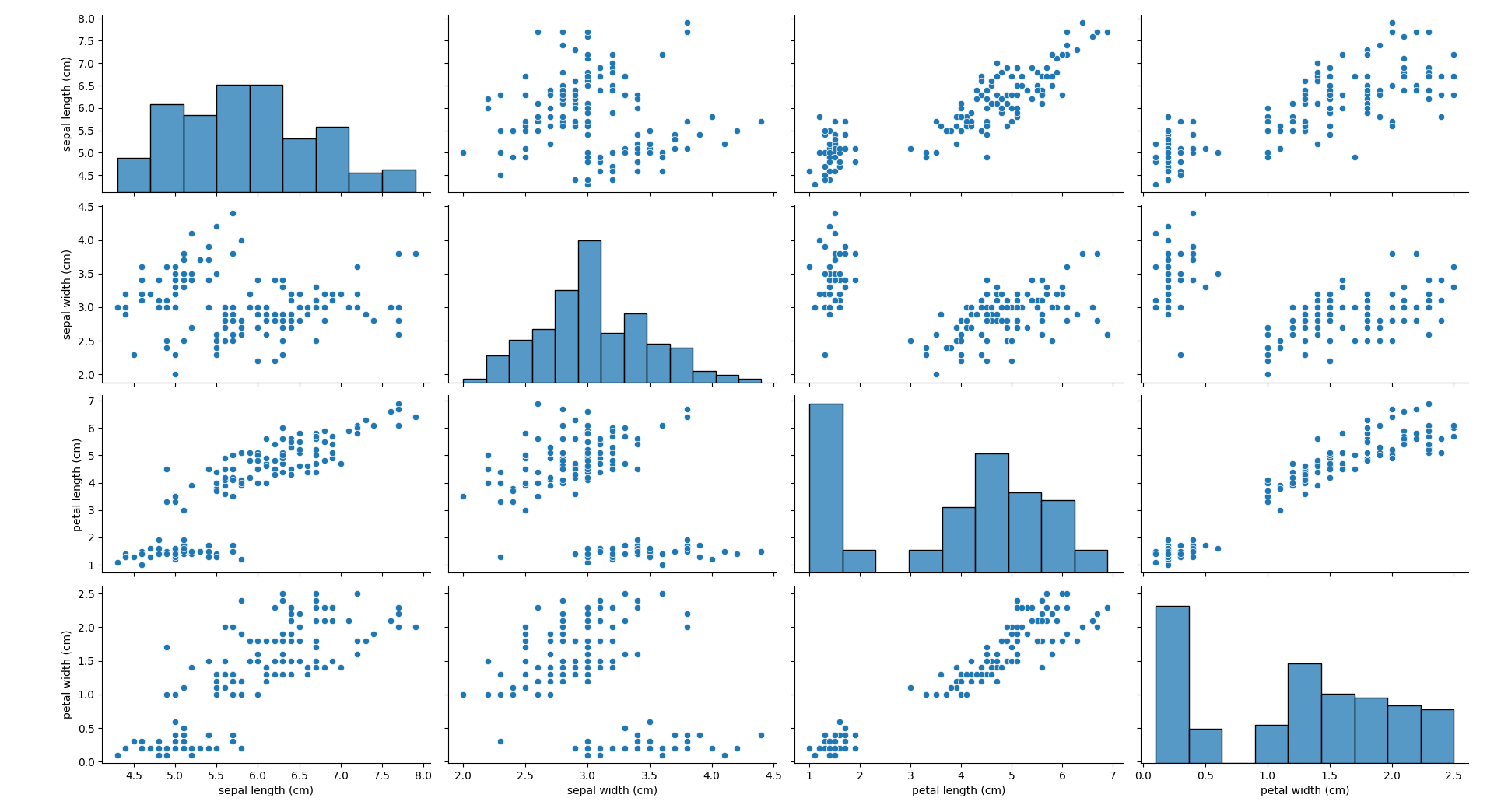
# 数据分析 - 可视化
df = pd.DataFrame(X, columns=data.feature_names)
sns.pairplot(df)
plt.show()
# 特征工程 - 标准化
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# 创建并训练SOM
som = MiniSom(x=10, y=10, input_len=4, sigma=1.0, learning_rate=0.5)
som.random_weights_init(X_scaled)
som.train_random(X_scaled, num_iteration=100)
# 定义mapped变量
mapped = np.array([som.winner(d) for d in X_scaled])
# 标记每个样本在SOM网格中的位置 - 优化显示
plt.figure(figsize=(10, 10))
for i, m in enumerate(mapped):
plt.plot(m[0]+.5, m[1]+.5, marker='o', color=plt.cm.rainbow(y[i] / 3.), markersize=12, alpha=0.5)
plt.xticks(range(10))
plt.yticks(range(10))
plt.grid()
plt.xlim([0, 10])
plt.ylim([0, 10])
plt.show()
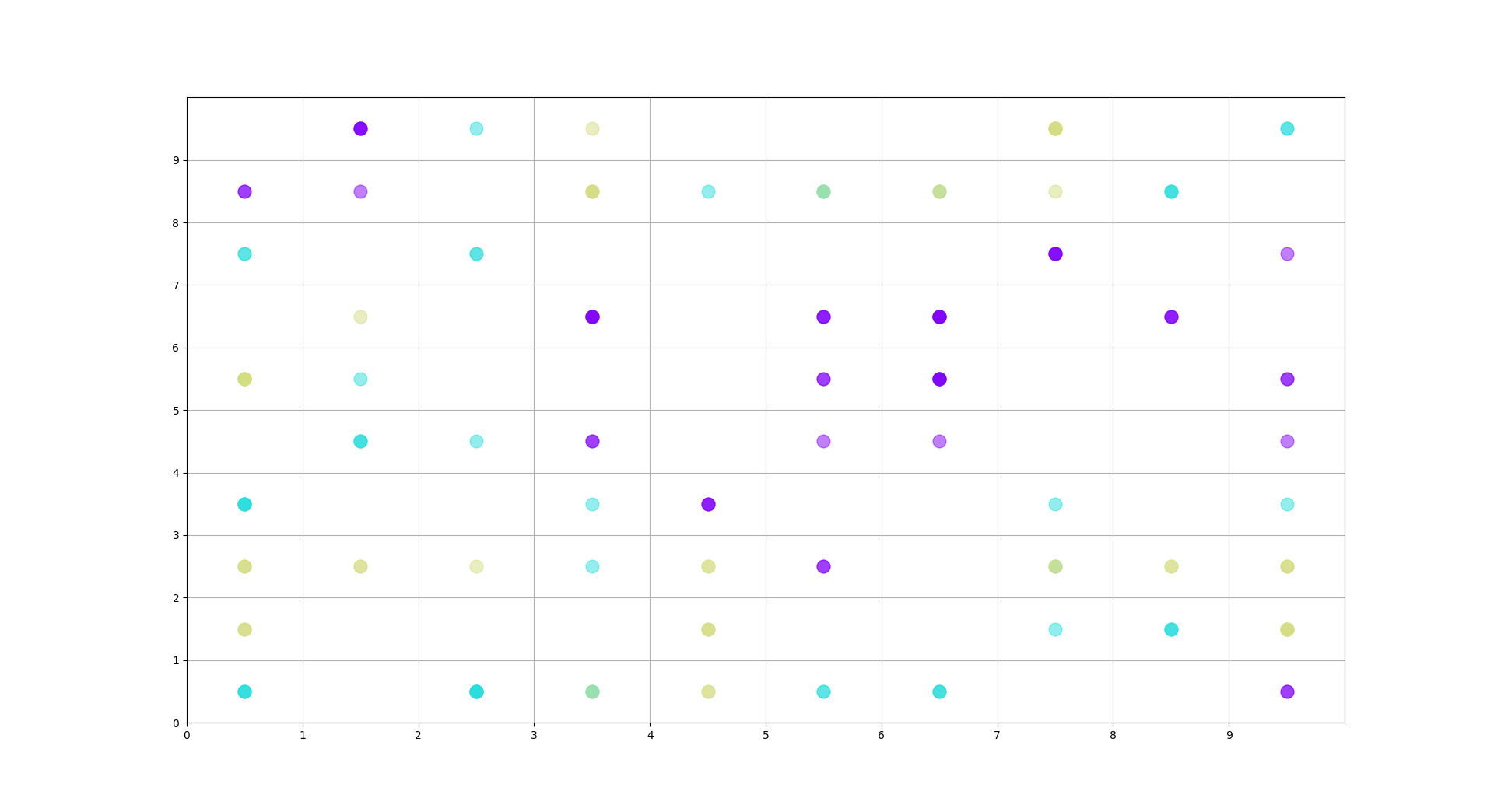
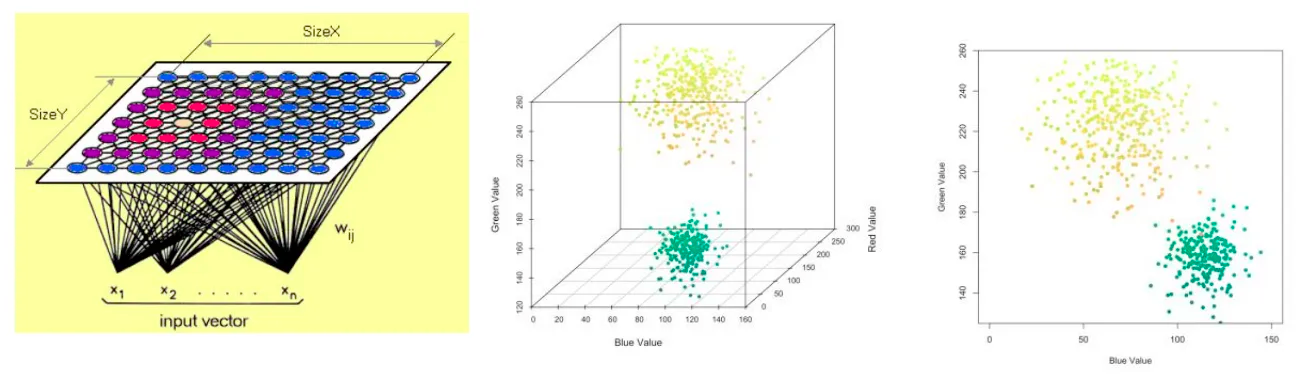
在SOM的结果中,相似的数据点被映射到彼此相邻的位置。通过观察SOM生成的图,我们可以直观地看到数据的聚类情况。数据点的分布和聚类可以揭示数据的内在结构和潜在的模式。
优化策略
优化SOM的关键在于正确选择网络的大小、学习率和邻域函数。此外,根据具体的应用场景,调整这些参数可以提高SOM的性能和准确性。
结论
自组织映射提供了一种强大且灵活的方法来分析和解释复杂的高维数据。通过其独特的自学习和自组织能力,SOM可以揭示数据中的潜在结构和模式,为数据科学家和研究人员提供了一个强大的工具。
虽然SOM在许多领域表现出色,但它在处理非常大规模的数据集时面临挑战。随着技术的发展,未来的SOM可能会集成更先进的算法,以提高其在大数据环境中的性能。
往期推荐
- 一文看懂机器学习
- 机器学习-房价预测建模
- 机器学习 | 基础术语与符号
- 机器学习 | 特征缩放
- 机器学习| K 近临(K Nearest-Neighbours)
- 机器学习| K邻近疾病预测演示
- 机器学习 | K均值聚类(K-means Clustering)
- 机器学习 | 朴素贝叶斯原理实战
- 机器学习 | 线性回归
- 机器学习 | 支持向量机线性可分
- 机器学习 | 支持向量机线性不可分
- 机器学习 | 非线性支持向量机
欢迎扫码关注公众号,订阅更多文章!